Collectl & Colplot Sytem Performance Analysis Tools
It is not often that I run into Unix performance analysis tool that, a), I haven’t seen before and, b), is worth my attention. Collectl is both. It is a very useful combination of iostat, vmstat, netstat and just about every other ‘stat. All of those standard tools are awesome for getting that specific piece of system performance information, but uniting all that data into one cohesive picture usually requires a Master’s degree in Awk & Sed programming.
Collectl is the business end of the tool, while Colplot is the Web CGI to make pretty plots out of Collectl logs. Without further ado, here are the basic installation steps for CentOS/RHEL/Fedora running Apache.
Install Collectl
v="4.0.2"
cd /tmp
wget http://downloads.sourceforge.net/project/collectl/collectl/collectl-${v}/collectl-${v}.src.tar.gz
gzip -d collectl-${v}.src.tar.gz
tar xvf collectl-${v}.src.tar
cd collectl-${v}
./INSTALL
which collectl
collectl
Install Colplot
v="5.0.0"
cd /tmp
wget http://downloads.sourceforge.net/project/collectl/Colplot/colplot-${v}.src.tar.gz
gzip -d colplot-${v}.src.tar.gz
tar xvf colplot-${v}.src.tar
cd colplot-${v}
./INSTALL
Configure Apache
homedir=/var/www/html/colplot
logdir=/var/log/httpd/colplot
domain=yourdomain.com
mkdir -p "${logdir}"
chown -R apache:apache "${logdir}"
chown -R apache:apache "${homedir}"
cat << EOF >> /etc/httpd/conf/httpd.conf
Listen 8080
<VirtualHost *:8080>
#ServerAdmin root@${domain}
DocumentRoot /var/www/html/colplot
ServerName colplot.${domain}
CustomLog ${logdir}/access_log combined
ErrorLog ${logdir}/error_log
<Directory "${homedir}/">
AllowOverride All
Options ExecCGI
AddHandler cgi-script .cgi
DirectoryIndex index.cgi
Options +followsymlinks +execcgi
Order allow,deny
Allow from all
</Directory>
</VirtualHost>
EOF
/sbin/service httpd restart
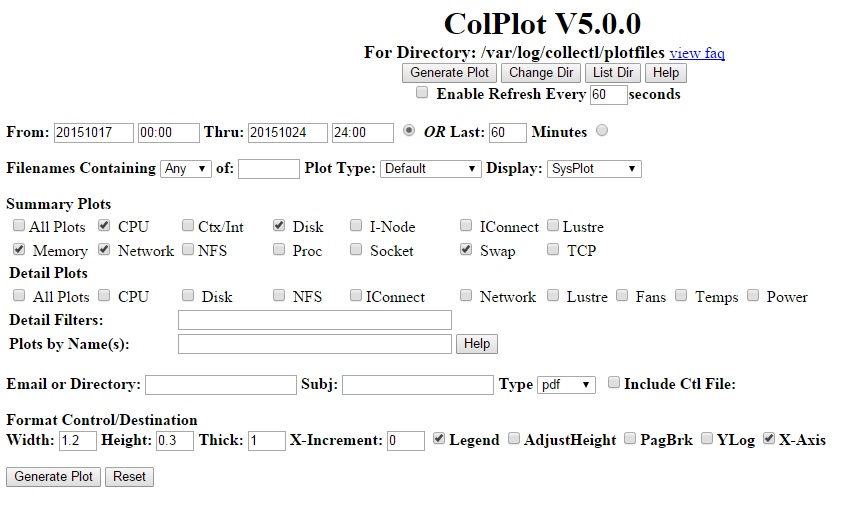
Configure Colplot
plotdir=/var/log/collectl/plotfiles
mkdir -p "${plotdir}"
sed -i 's@^PlotDir.*=.*/var/log/collectl@PlotDir = /var/log/collectl/plotfiles@g' /etc/colplot.conf
Generate plot files
find /var/log/collectl -maxdepth 1 -mindepth 1 -type f -name "*\.raw\.gz" | sort -t'-' -k2 -n | while read line ; do collectl -p "${line}" -P -f /var/log/collectl/plotfiles -ocz 2>/dev/null & disown
done
1
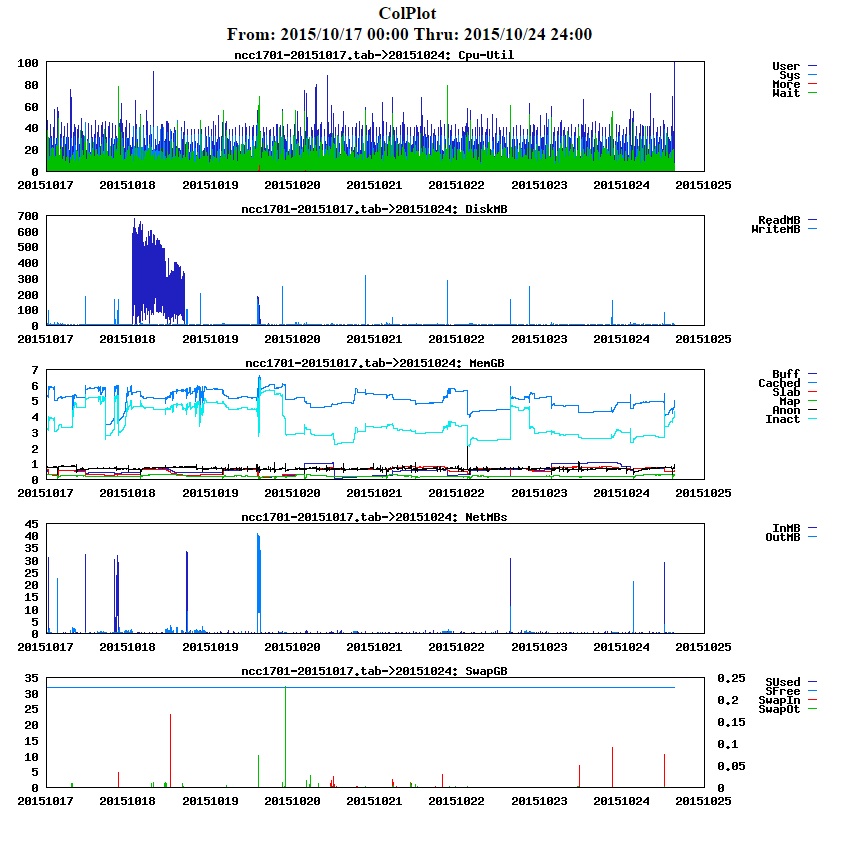
Collectl tutorial and documentation can use some work. More examples of practical use would be nice.
[root@ncc1701 ~]# collectl -scjmdintsf -oD waiting for 1 second sample... # <--------CPU--------><--Int---><-----------Memory-----------><----------Disks-----------><----------Network----------><-------TCP--------><------Sockets-----><----Files---><------NFS Totals------> #Date Time cpu sys inter ctxsw Cpu0 Cpu1 Free Buff Cach Inac Slab Map KBRead Reads KBWrit Writes KBIn PktIn KBOut PktOut IP Tcp Udp Icmp Tcp Udp Raw Frag Handle Inodes Reads Writes Meta Comm 20150826 11:14:23 0 0 883 465 45 838 2G 186M 3G 3G 170M 976M 896 14 0 0 20 278 765 520 0 0 0 0 380 0 0 0 1760 25225 0 0 0 0 20150826 11:14:24 34 1 2035 1859 610 1426 2G 186M 3G 3G 170M 980M 1536 24 0 0 31 443 1335 903 0 0 0 0 383 0 0 0 1760 25229 0 0 0 0 20150826 11:14:25 9 1 1709 1264 187 1521 2G 186M 3G 3G 170M 976M 1536 24 380 78 42 612 1902 1284 0 0 0 0 383 0 0 0 1760 25231 0 0 0 0 20150826 11:14:26 78 3 2699 2869 802 1898 2G 186M 3G 3G 170M 982M 1032 18 338 76 32 451 1197 812 0 0 0 0 385 0 0 0 1792 25235 0 0 0 0 20150826 11:14:27 5 0 1102 1127 181 920 2G 186M 3G 3G 170M 976M 896 14 510 89 27 386 1136 769 0 0 0 0 381 0 0 0 1792 25229 0 0 0 0 20150826 11:14:28 0 0 240 223 136 104 2G 186M 3G 3G 170M 976M 128 2 0 0 10 137 358 242 0 0 0 0 381 0 0 0 1792 25229 0 0 0 0 20150826 11:14:29 1 0 449 328 140 309 2G 186M 3G 3G 170M 974M 384 6 0 0 5 74 208 141 0 0 0 0 381 0 0 0 1792 25229 0 0 0 0 20150826 11:14:30 1 0 1029 513 142 888 2G 186M 3G 3G 170M 976M 1024 16 0 0 17 246 724 489 0 0 0 0 381 0 0 0 1792 25230 0 0 0 0

- Note: the above syntax will run collectl file conversion in parallel for all *.raw.gz files in the log directory (by default, Collectl will keep 8 days of data). This would make things go faster on a multi-CPU system with a good amount of RAM. On a system with modest resources, drop the “&disown” part to run file conversion sequentially.
![wyryr1sn52gntzn65v4fpz5lc6v[1]](https://i2.wp.com/www.krazyworks.com/wp-content/uploads/2021/08/wyryr1sn52gntzn65v4fpz5lc6v1-80x80.jpg "Plundering Facebook Photo Albums")
![clfud46mxf2t5zph2l04zlpgl1d[1]](https://i2.wp.com/www.krazyworks.com/wp-content/uploads/2021/08/clfud46mxf2t5zph2l04zlpgl1d1-80x80.jpg "Scraping a Web Page in Bash")
![DSCF5361[1]](https://i1.wp.com/www.krazyworks.com/wp-content/uploads/2020/10/DSCF53611-80x80.jpg "Processing Videos with ffmpeg and Lightroom")
![Cat-Devouring-A-Bird-Pablo-Picasso[1]](https://i0.wp.com/www.krazyworks.com/wp-content/uploads/2020/10/Cat-Devouring-A-Bird-Pablo-Picasso1-80x80.jpg "Searching Twitter")
![91ebozy1e3b138waujy28agrngy[1]](https://i2.wp.com/www.krazyworks.com/wp-content/uploads/2021/08/91ebozy1e3b138waujy28agrngy1-80x80.jpg "Generating Random Text Files for Testing")
![iwoau71okwxqh4jv3k4ook32qps[1]](https://i2.wp.com/www.krazyworks.com/wp-content/uploads/2021/08/iwoau71okwxqh4jv3k4ook32qps1-80x80.jpg "Finding Cron Jobs")
![5gtysva4wkc8mzc1k3e66vaycxx[1]](https://i1.wp.com/www.krazyworks.com/wp-content/uploads/2021/08/5gtysva4wkc8mzc1k3e66vaycxx1-80x80.jpg "Understanding Memory Utilization in Linux")
![sy2zeb1vp2h8itlxfbbylw0jrm0[1]](https://i0.wp.com/www.krazyworks.com/wp-content/uploads/2019/12/sy2zeb1vp2h8itlxfbbylw0jrm01-80x80.jpg "Validating HTTPS Cache Peers for Squid")
![Photo-2019-10-07-14-39-03_0266[1]](https://i1.wp.com/www.krazyworks.com/wp-content/uploads/2019/11/Photo-2019-10-07-14-39-03_02661-80x80.jpg "Verifying SNMP Connectivity on Multiple Hosts")

If you haven’t had a chance to look at colmux yet you should! Think of collectl/top across a cluster, sorted by any column. I’ve used it to find the slowest disks out of thousands across hundreds of nodes. no system manager should be without it in their toolbag. You can even playback historical data and look for anomalies in it.
-mark